February 4, 2025
🌟 New Features
- AI-Powered Data Transformations: Easily derive new columns by simply specifying the transformation or enrichment you need. For example, ask AI to extract the weekday from a date, calculate the days between two dates, or classify customers as professionals based on their email domain— and much more.
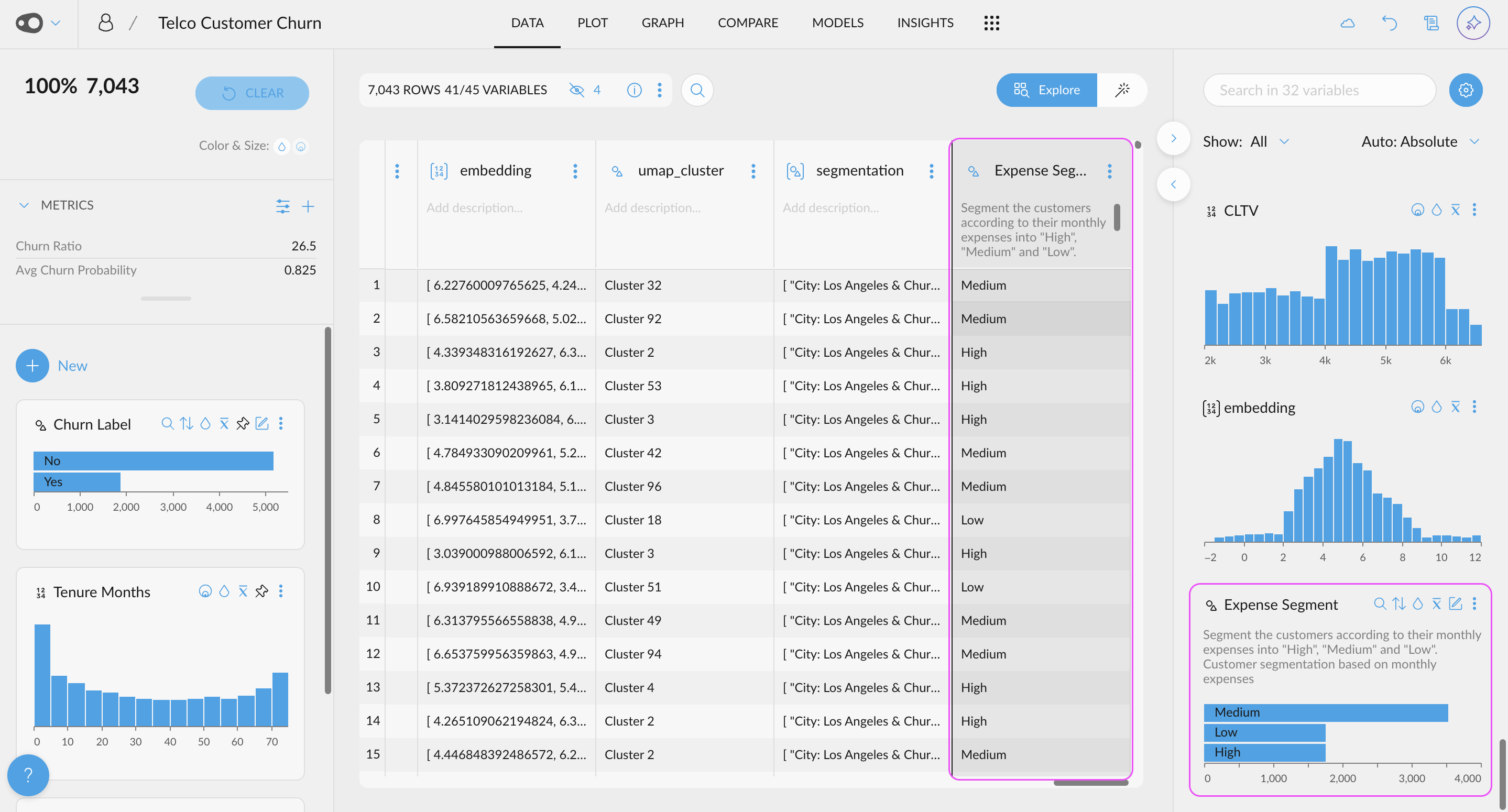
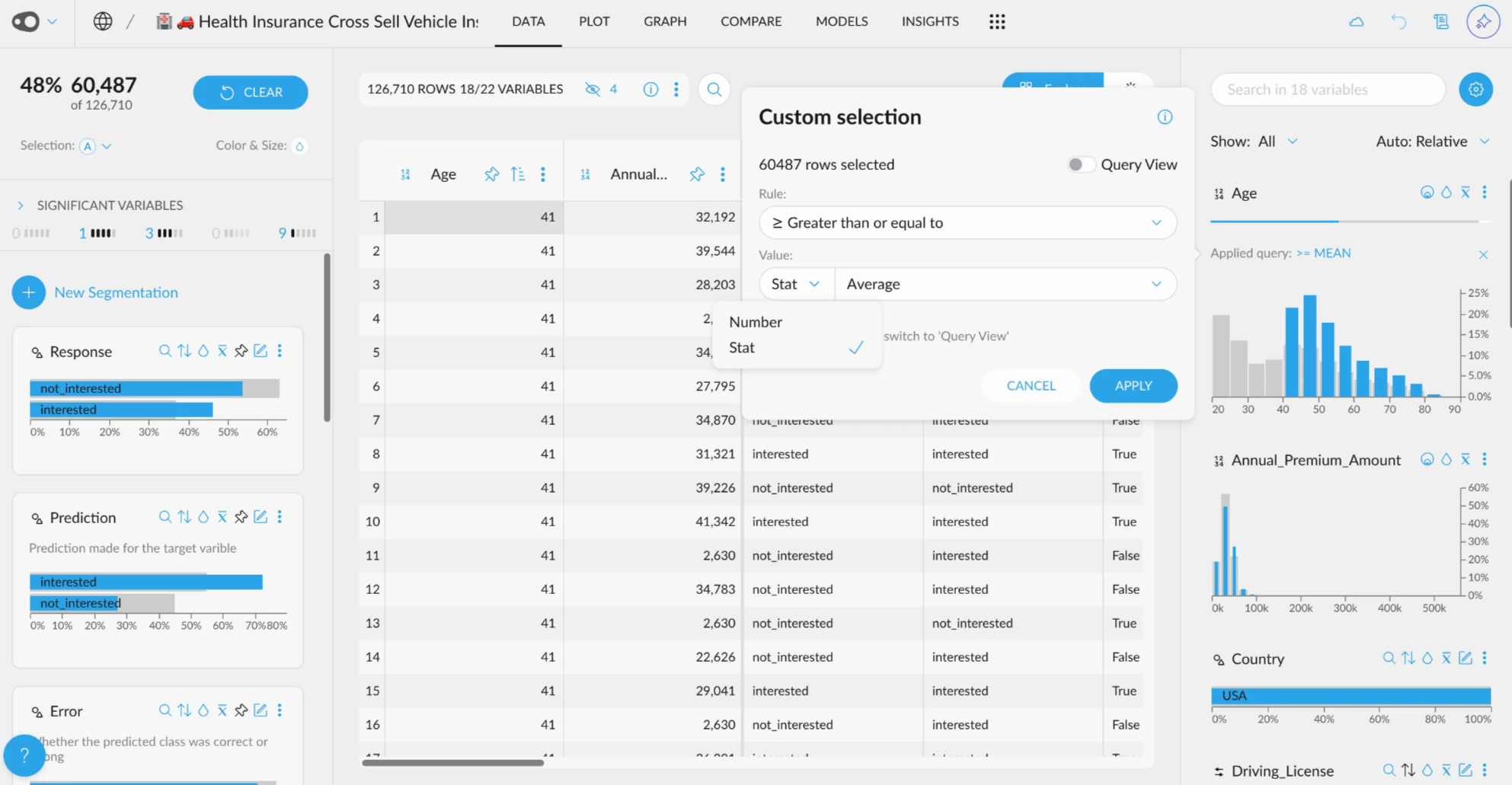
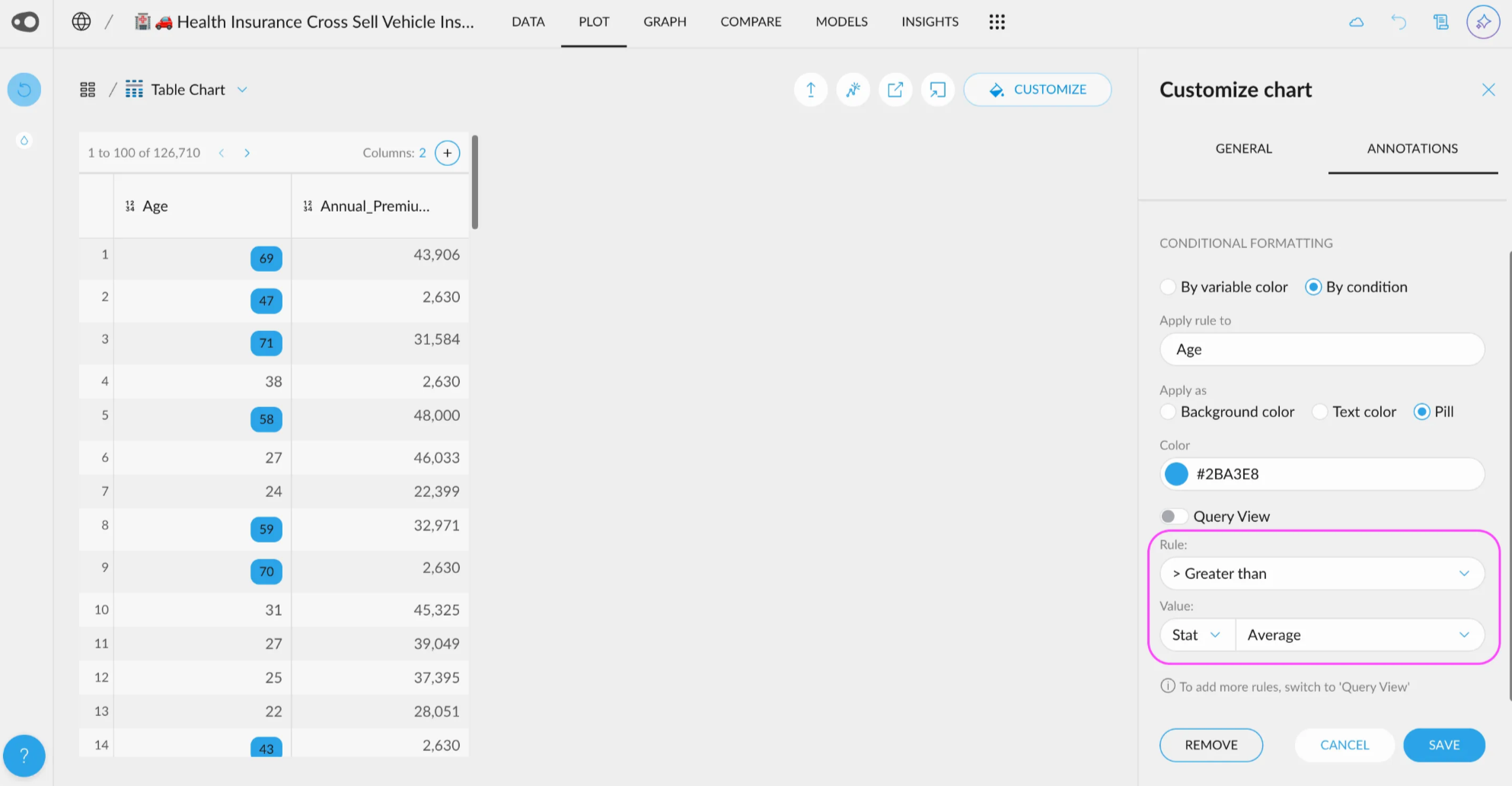
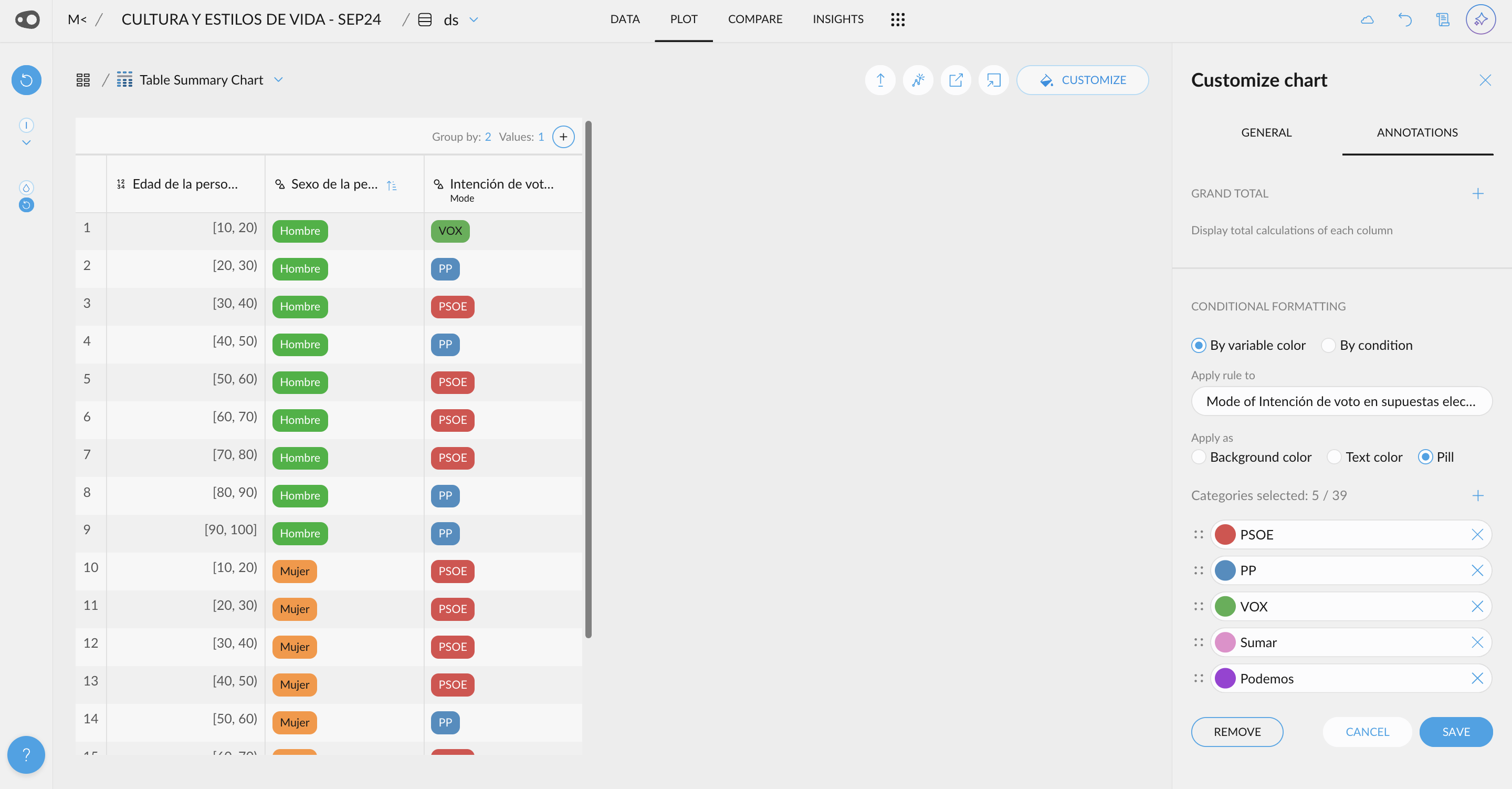
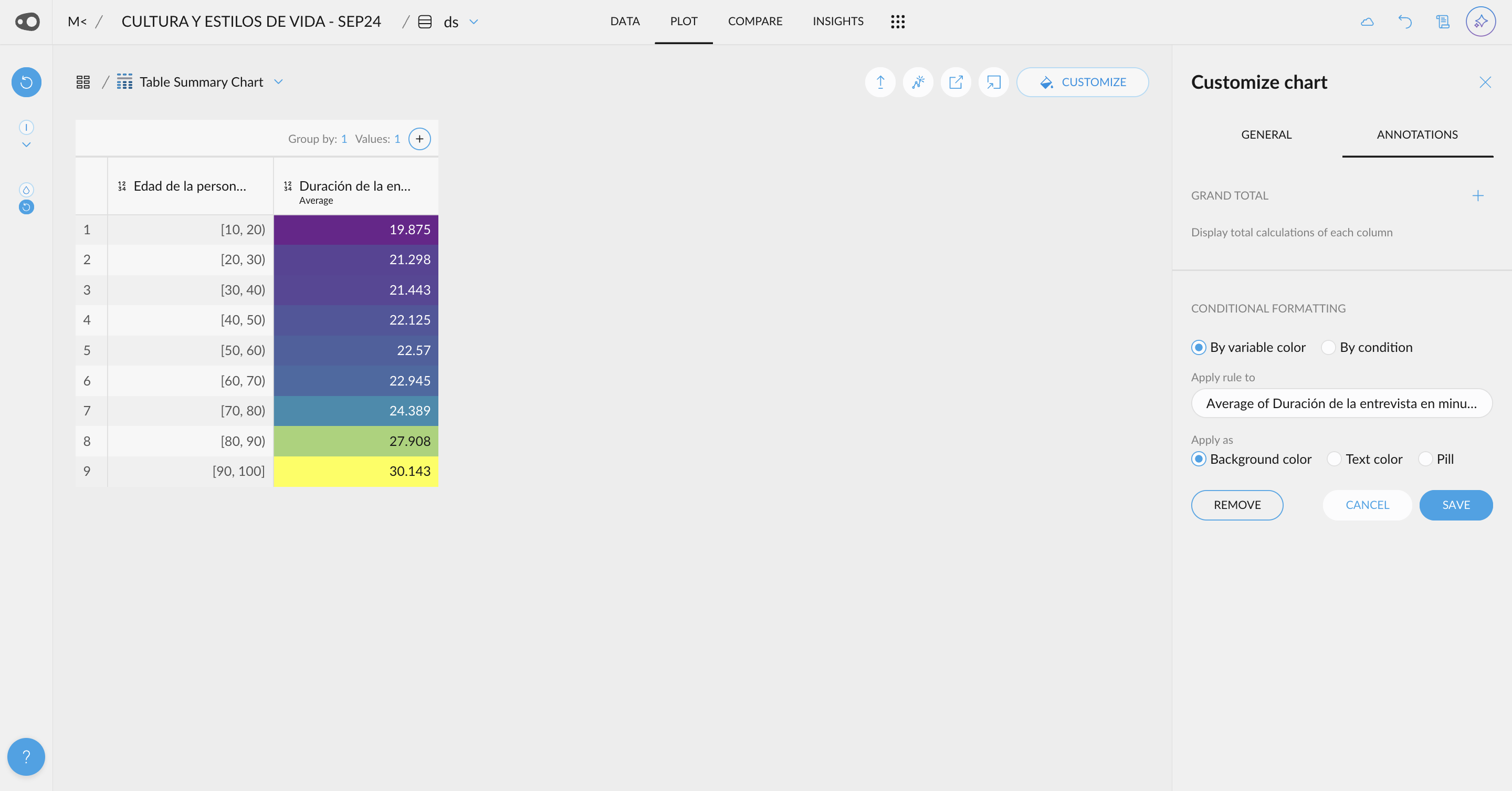
- Add multiple rules for coloring. Now, you can add multiple rules per column. Duplicating rules is also allowed, making it easier to color cells!
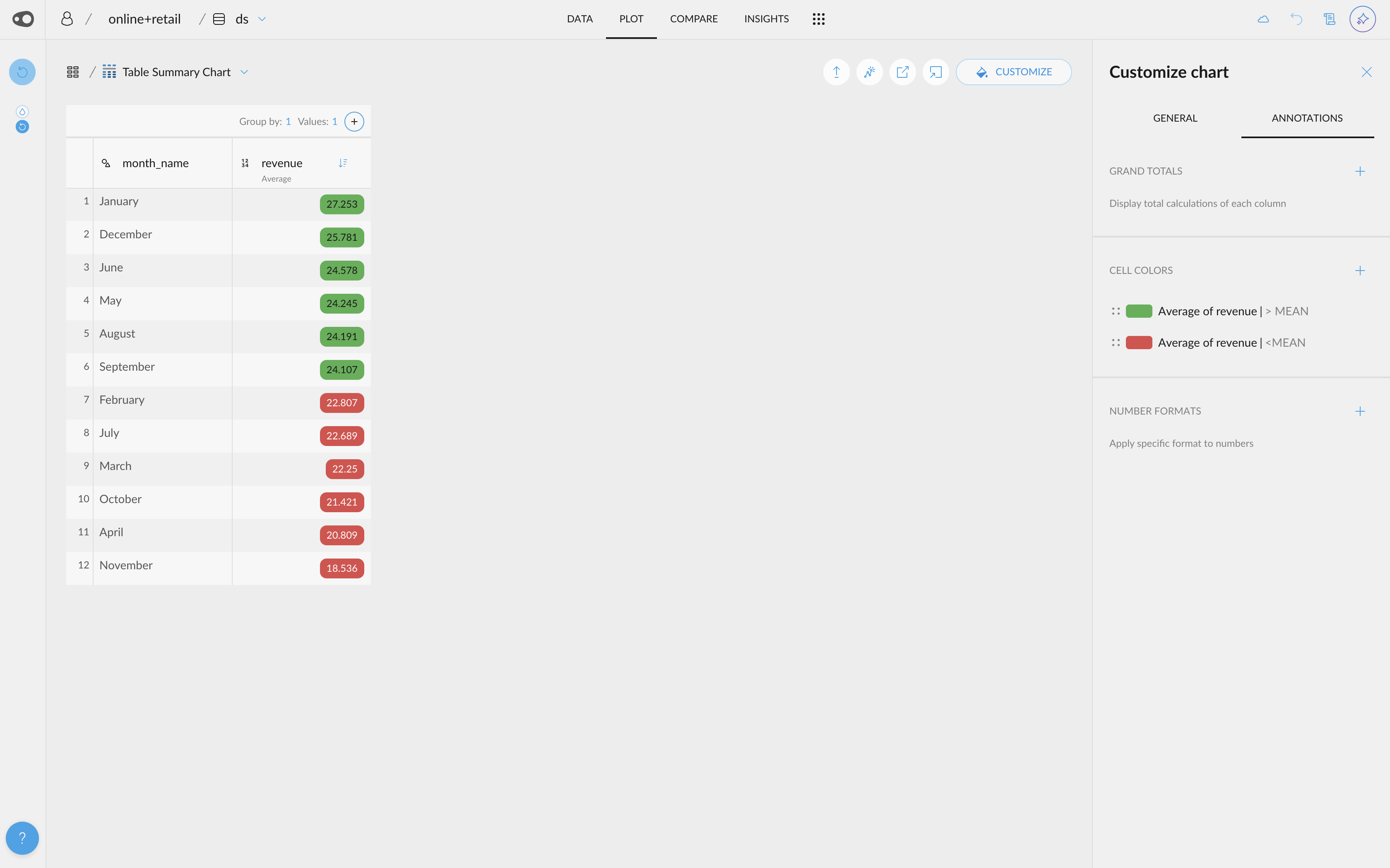
- New shortcuts are accessible from the omnibar. For example, if you want to go to the plot section or share your project, you can find it there!
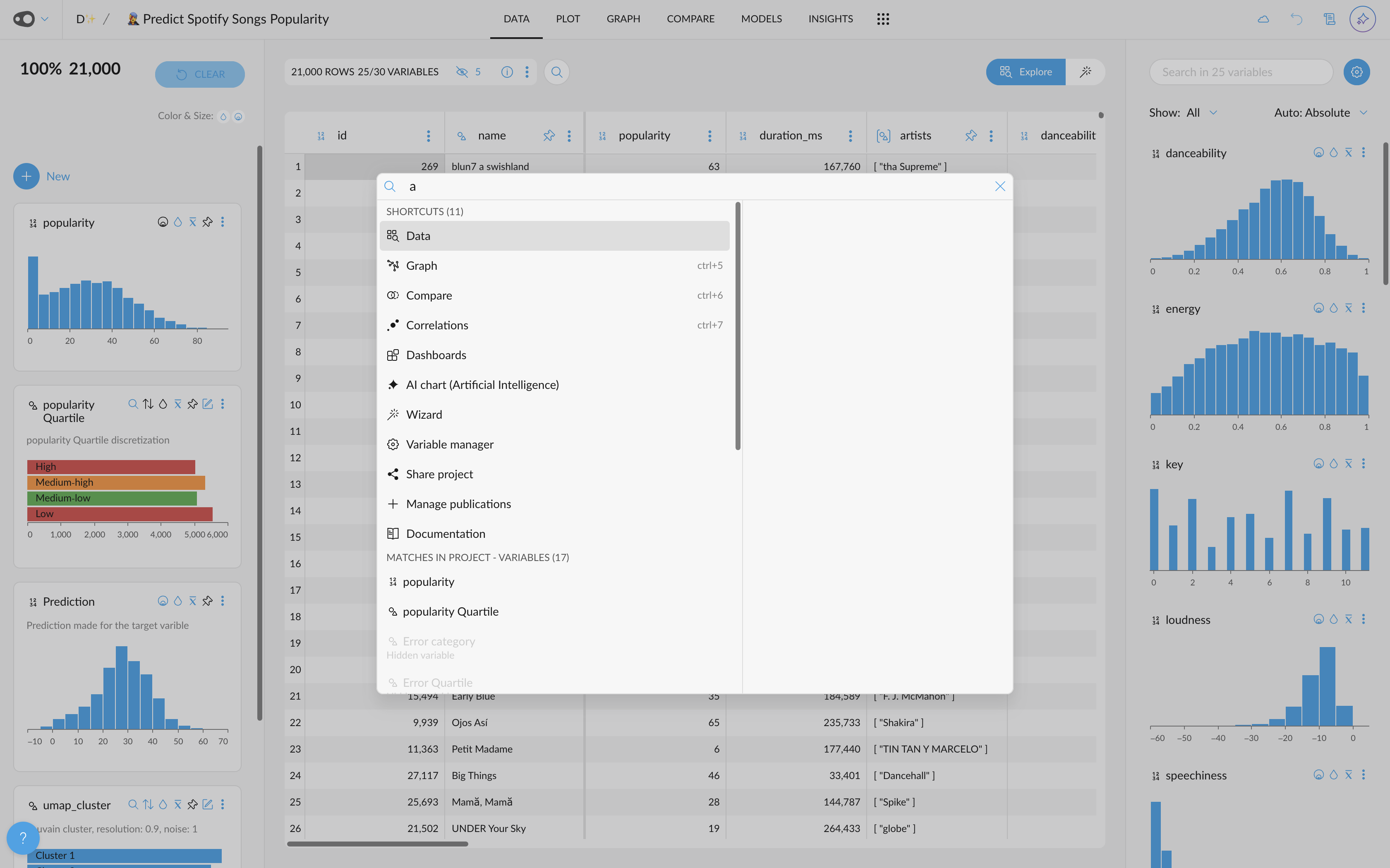
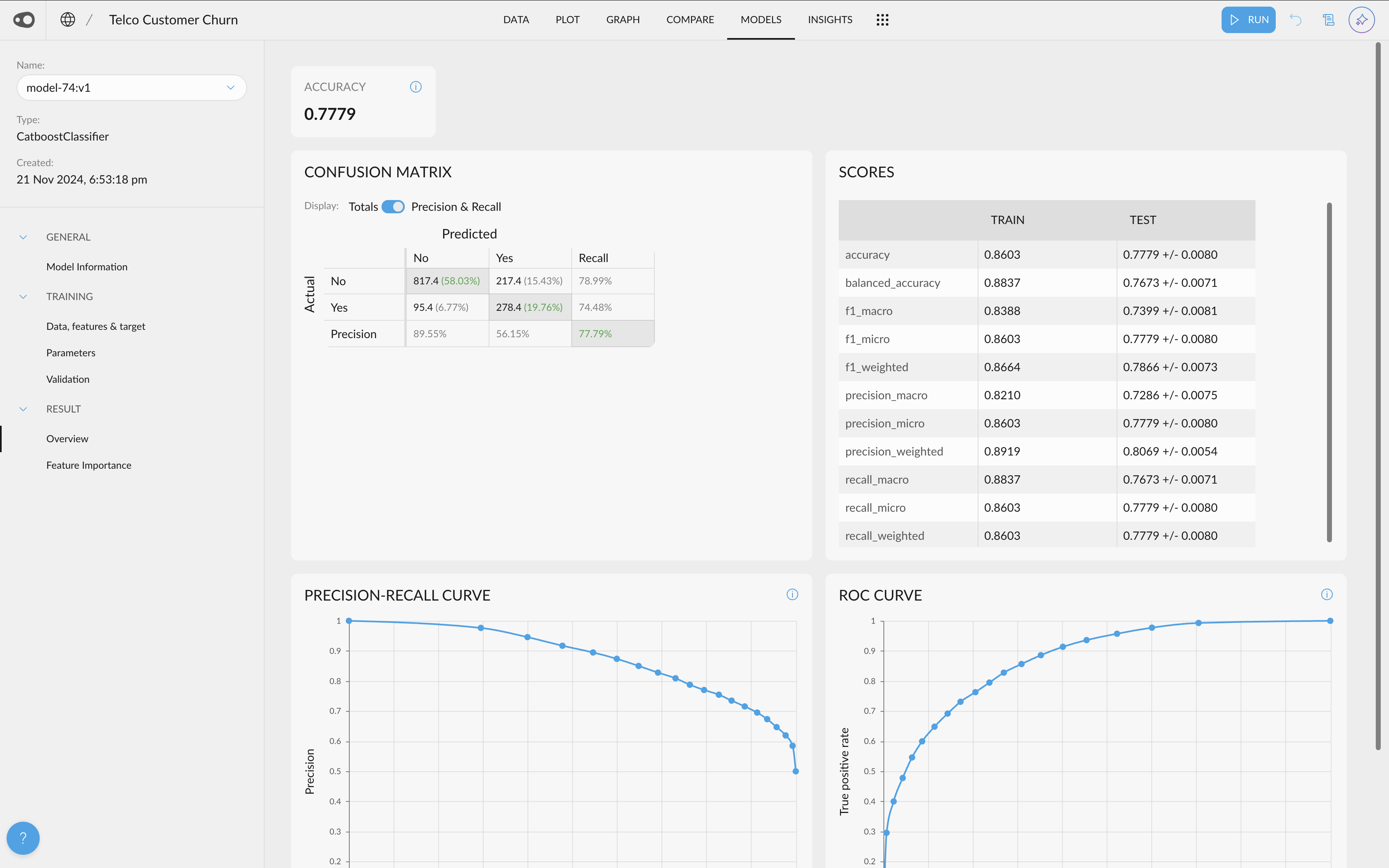
- Models Preprocessing Steps: The preprocessing tab has been included in the Models section. We do a lot of magic under the hood when creating your predicitve models. Now we make it available for you in the models tab
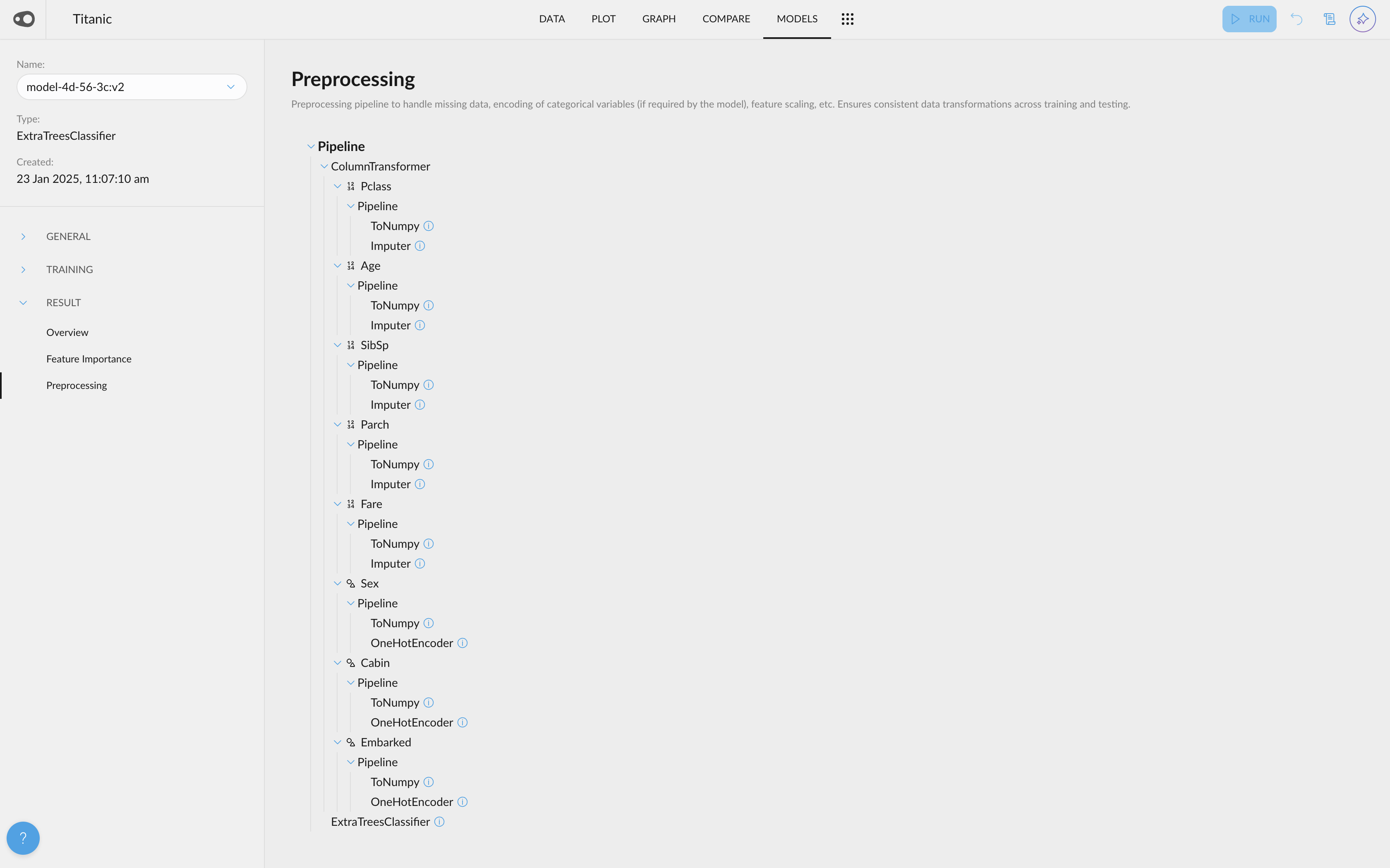
- Shortcut to create new metrics: We've introduced a special "New" button that allows you to easily create segmentations (both automatic and manual) and metrics.
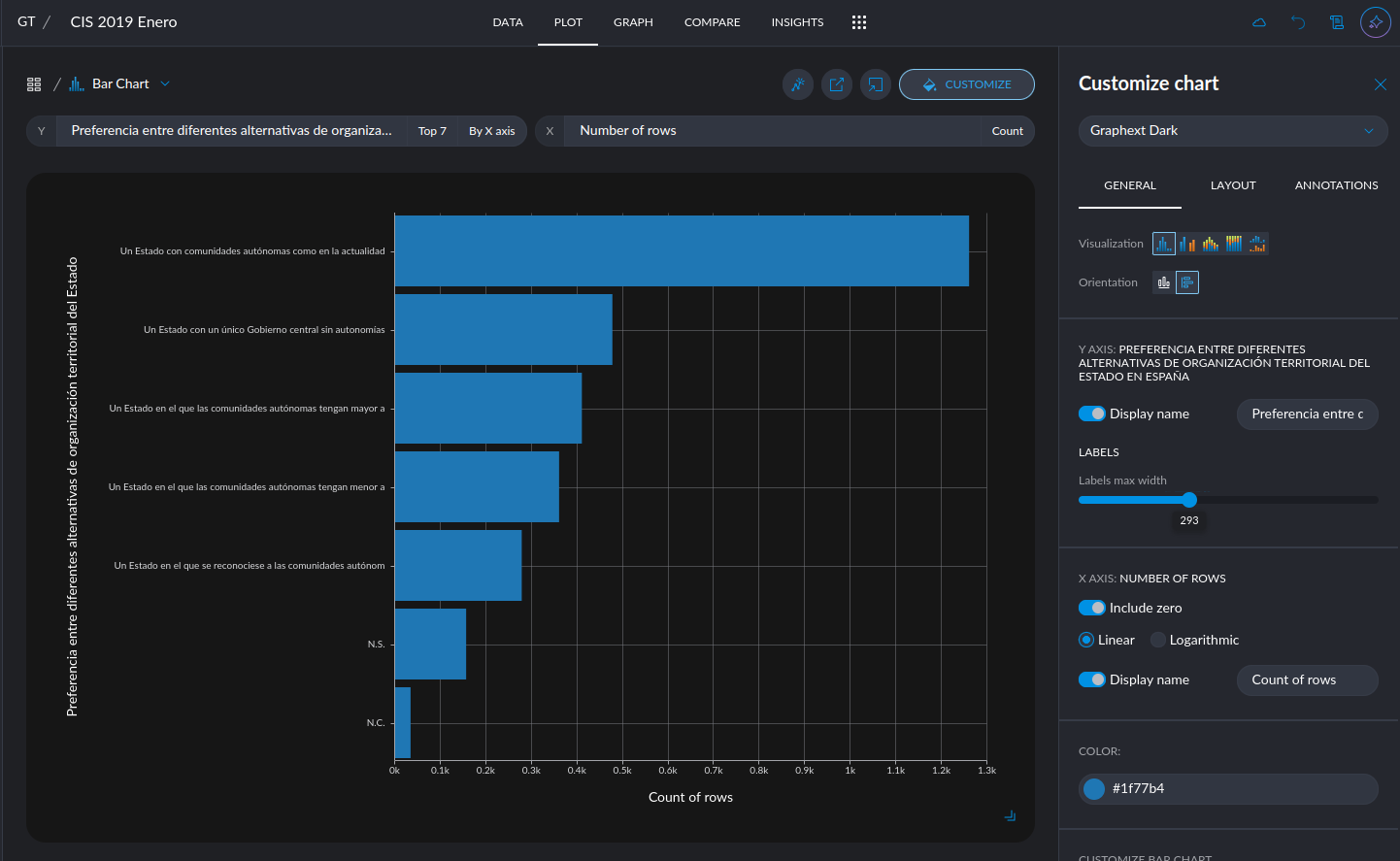
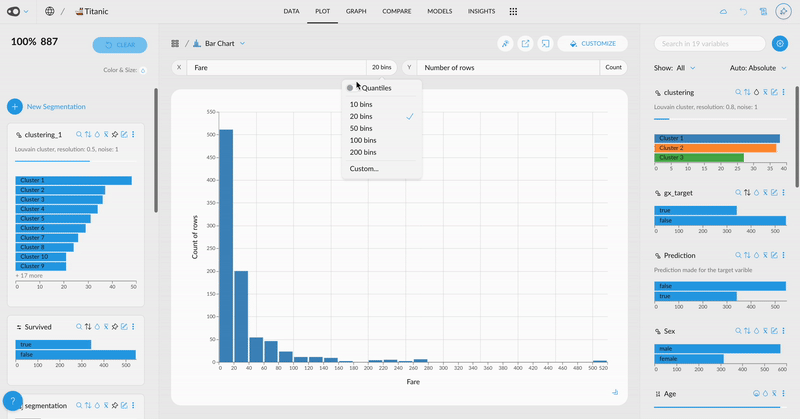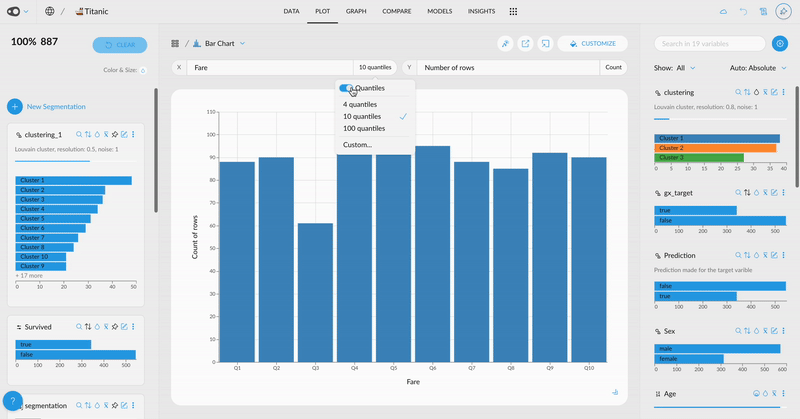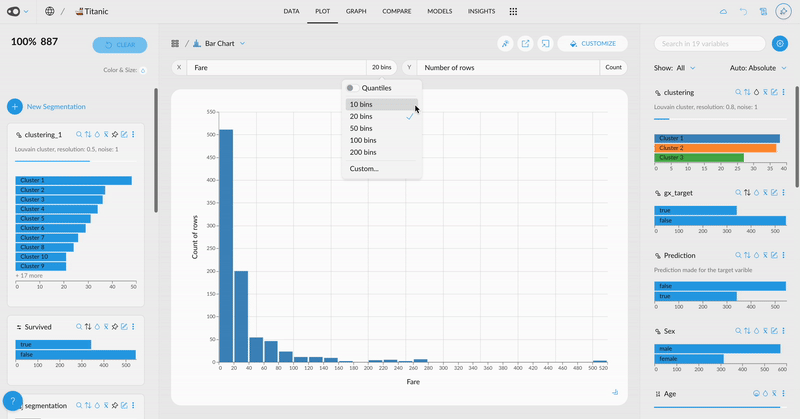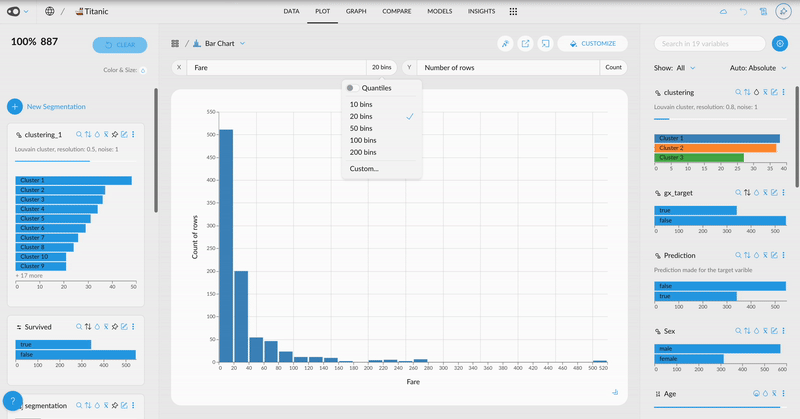
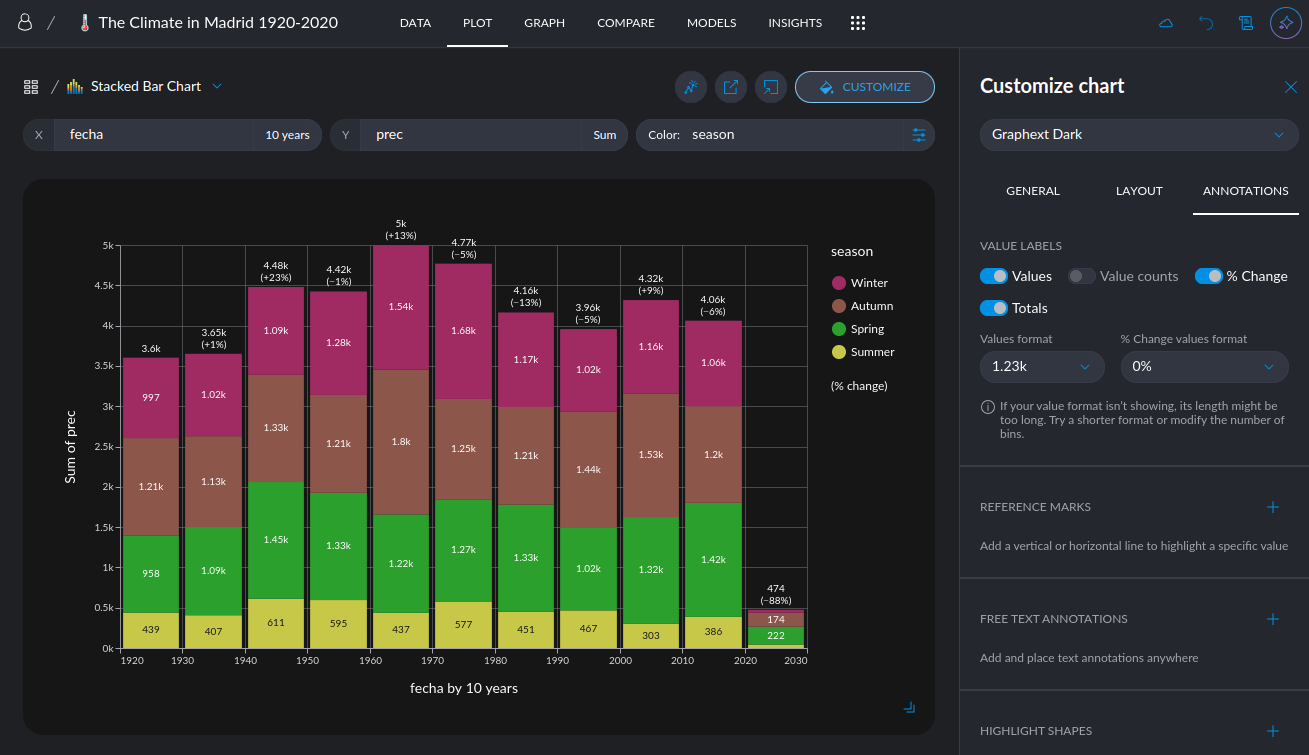
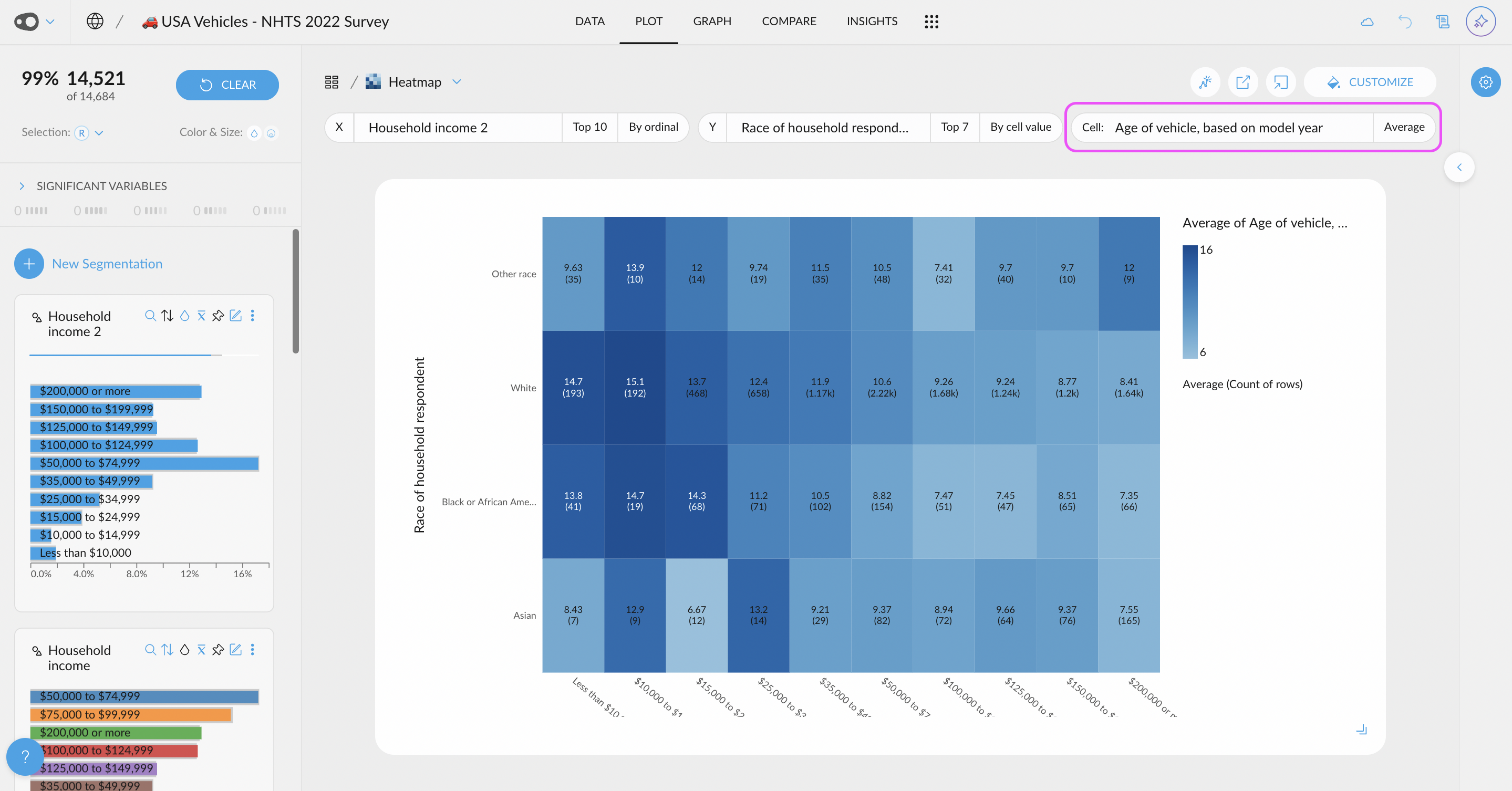
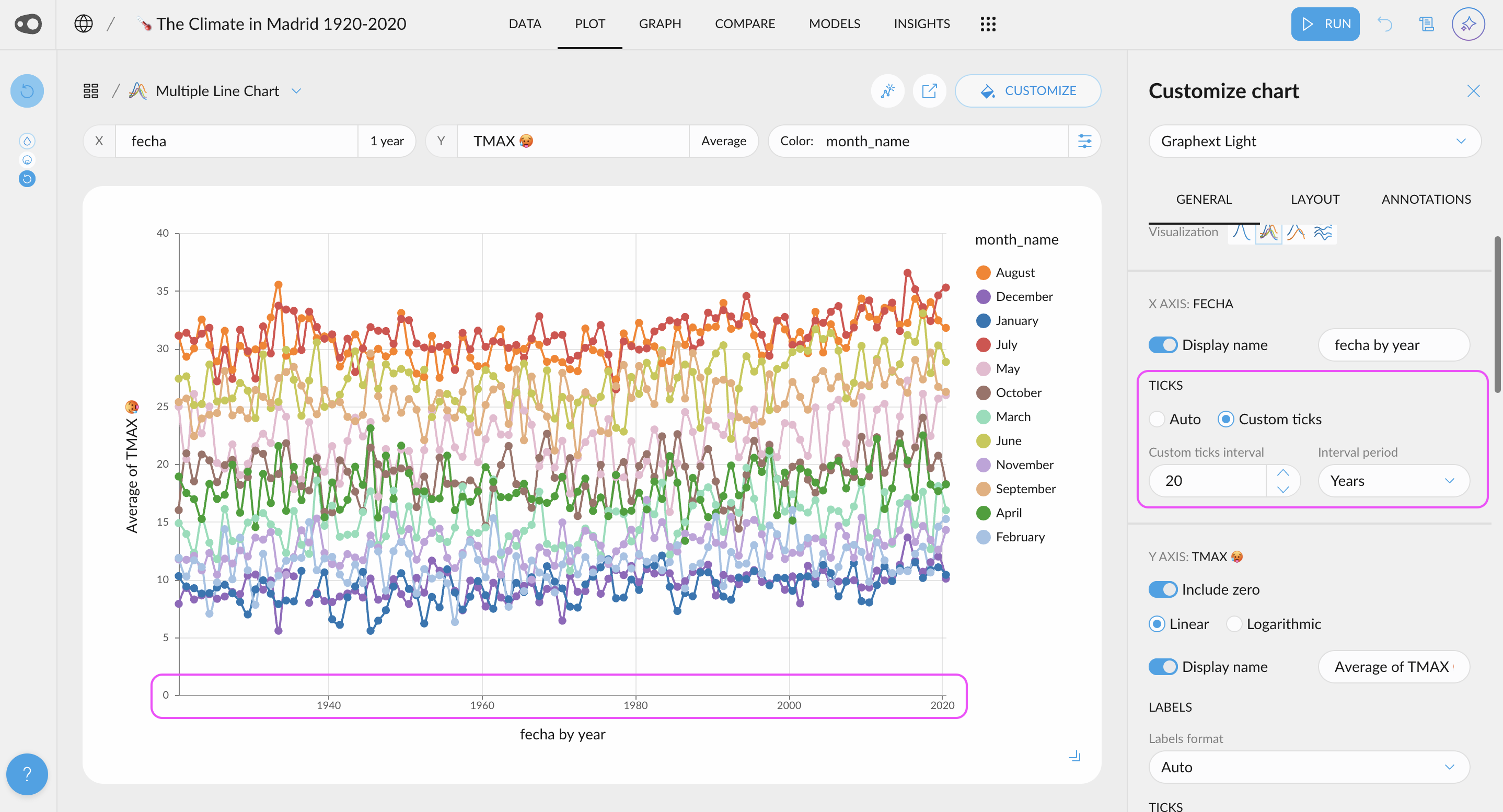
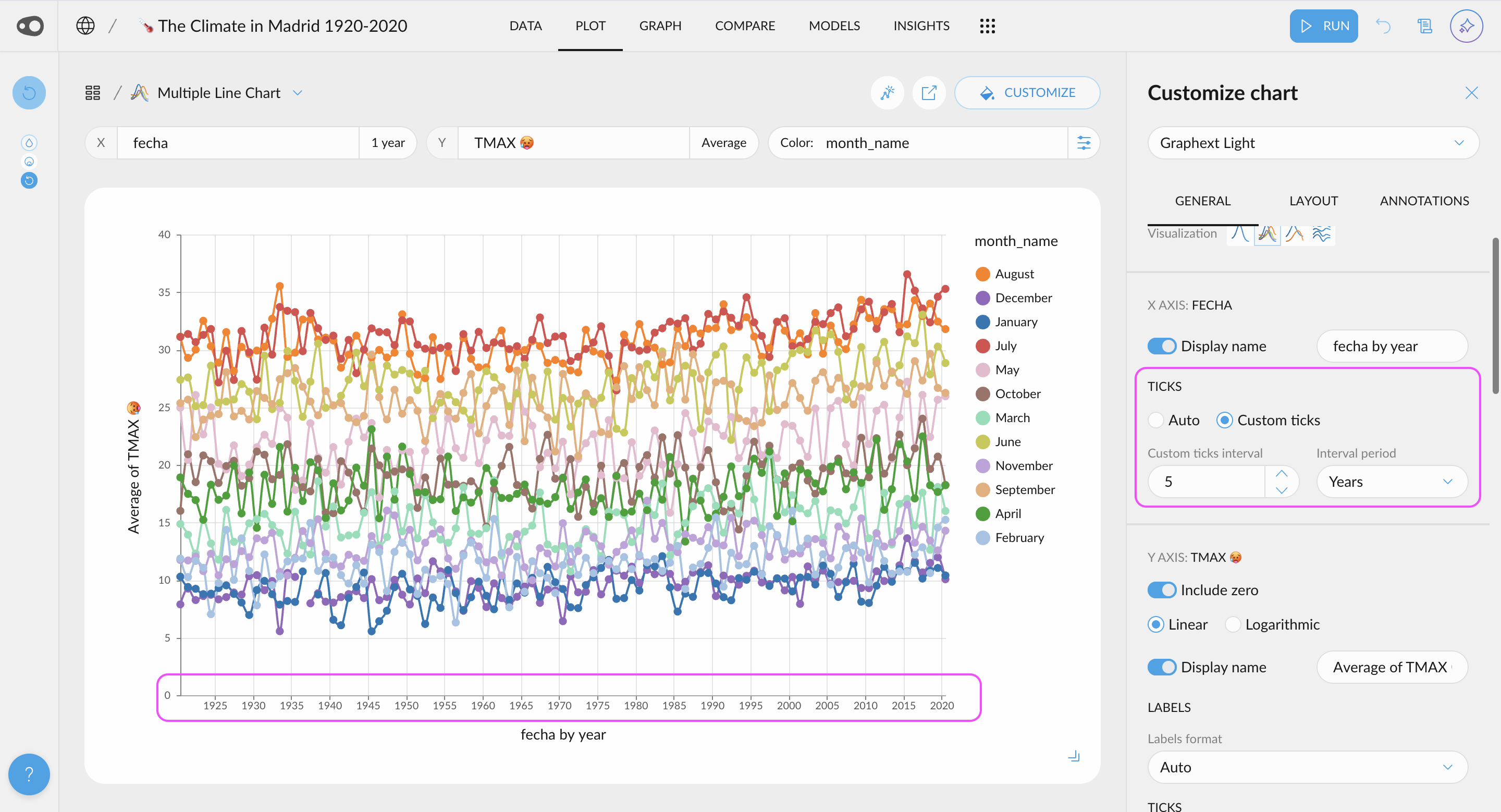
- Customize Ticks in Plots: Choose to display more or fewer ticks or even specify exact values. This flexibility helps you tailor your visualizations for clearer and more effective communication of insights.
🎨 UI Updates
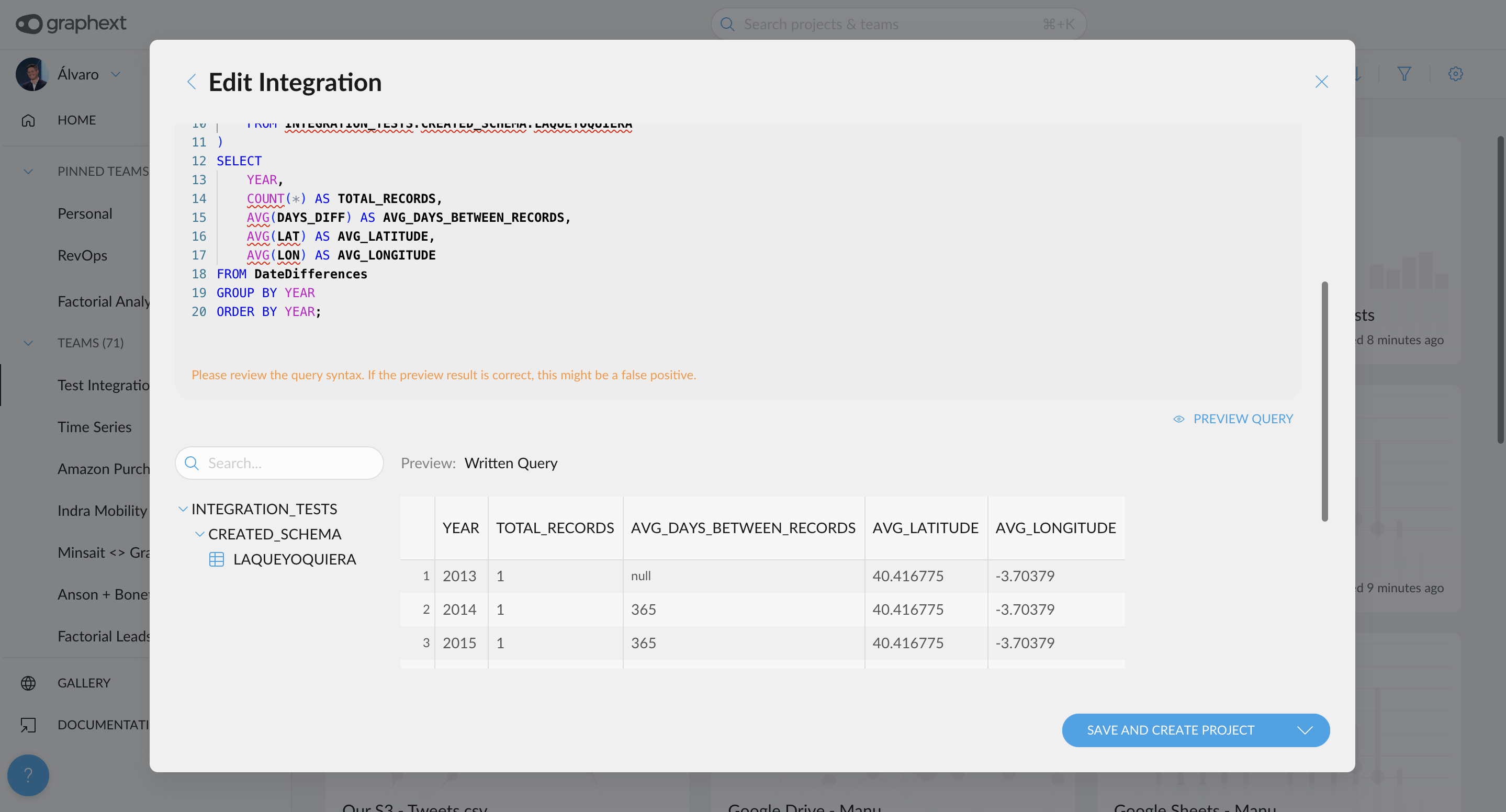
- Formatting and Autocomplete for Queries: We've added a code editor with SQL formatting for integration queries, along with autocomplete for table and variable names. This makes it easier to spot errors and write queries faster.
- Nested sections in Models sidebar. Sections now display their subsections in the sidebar, making them easier to access.