Mastering a Career in Data Science
Do you want to learn about data science? Are you starting out in programming? Well, embarking on a journey into the realm of data and programming can be both exciting and overwhelming, especially for newcomers. Whether you are a beginner or just starting out, preparing yourself and understanding the world you are about to dive into is crucial.
Here, we will explore experiences of fellow users in Kaggle - a popular online community for data scientists and machine learning practitioners - and gather insights that will give you a comprehensive glimpse into the world of data and programming as well as guidance to help you navigate this rapidly evolving field. In this exploration, we will be covering topics such as the diverse job roles and tools in the data and programming world, their use of Machine Learning, how they are able to secure high-paying jobs, the scope of their responsibilities, and suggestions on how to begin your own learning journey.
The dataset we are using is the "2022 Kaggle Machine Learning & Data Science Survey", which consists of a total of 43 questions answered by 23,997 respondents, posted by Kaggle in November 2022.
Here are some of the key findings that will inform our exploration:
- Python Dominates: Python is the most extensively used language in the data science and programming world, utilized across various roles with an average usage rate of 40.6%.
- Machine Learning is Crucial: Machine learning knowledge is a highly desirable skill. Among various ML methods, Linear/Logistic Regression is the most commonly used.
- Coding Experience Outweighs ML Experience for Compensation: Coding experience often leads to higher compensation than machine learning experience, signaling the value of practical coding skills.
- Preference for Non-traditional Learning Resources: Online platforms like Kaggle, online courses, and video platforms are the preferred learning resources, overshadowing traditional education pathways.
These findings suggest that ongoing learning and hands-on experience, rather than just formal education, are key to your success. Whether you are a beginner or just starting out, these insights will help you prepare and navigate the data science and programming world. So let's dive into this rapidly evolving field and guide you on how to begin your own learning journey.
Understanding Job Roles and Tools in Data Science and Programming
To kick things off, let’s begin by gaining an understanding of the diverse job roles in the data and programming world and how they are distributed.
We can see the different roles that are mainly held by users in this field. Notice that:
- The highest number of users work as data scientists with a whopping 1.93K, that's about 24% of our sample
- These are followed by 1.54K data analysts and 980 software engineers.
- Statisticians on the other hand are underrepresented, with only 125 individuals.
What are the Responsibilities and Skills for each Role?
With a clearer picture of the prevalent roles, you might still be wondering about the responsibilities and requisite skills for each role. So let’s delve into the most widely used programming languages and IDEs (Integrated Development Environment, a software application that helps write code) associated with each role.
We can see here that Python is dominating with 40.6% average usage rate, followed by SQL with an average usage rate of 24.8%. Interestingly, statisticians heavily rely on R more, with a usage rate of 30.5%, surpassing their usage rate of SQL which stands at 21.5%, likely because of R's strong statistical orientation. Software Engineers, on the other hand, use Java/Javascript more compared to other roles, with a usage rate of 24.8%, significantly surpassing the average of 10% among other roles. Teachers/professors however, showcase a relatively balanced distribution across programming languages, with Python retaining its prominence.
JupyterLab / Notebook is the most popular IDE, followed by VSCode. While JupyterLab / Notebook is mainly the most favored, some roles use other IDEs to quite a great extent too, for instance statisticians who utilize RStudio more, or software engineers who utilize VSCode more.
These insights give us better clarity in shaping our learning path, knowing which languages align with our desired roles and which IDE is the most popularly used.
The Importance of Machine Learning Expertise in Data Science Careers
You may also have heard of Machine Learning, which is more challenging to grasp than just knowing programming languages. However, do you really need to learn it? To answer that question, we will look at this chart below.
How many companies already incorporate Machine Learning into their business?
The majority of job roles in the “Data/Engineer'' category have already embraced ML to some extent, although not always in a fully integrated manner. We can see especially among MLops engineers, a mere 5.7% do not utilize ML at all in their workplace. Similarly, data scientists have a very low percentage of only 8% in this regard. Now a new question pops up. Do the companies that incorporate ML actually give better compensations? Here, I made a compensation heatmap of job roles that do not use Machine Learning.
Now let’s compare that to the compensation heat-map of job roles with well established Machine Learning methods.
Compensation Will be Higher for ML Established Companies
The companies that don’t utilize ML mainly pay yearly compensation of under $3K, while the companies that already have well established ML methods have higher yearly compensation, mostly distributed in the $50K - 500K range. Doesn’t this excite you to start learning Machine Learning? If you are wondering where to start, firstly, you need to have a better understanding of the diverse types of ML and know which are important to learn. Here we will examine the most popularly used ones within the survey.
Linear/Logistic Regression stands out as the most commonly used ML algorithms, followed by Decision Trees or Random Forests, while Evolutionary Approaches are less common. Therefore, it is highly advisable to start or prioritize learning at least Linear/Logistic Regression as it not only enhances your skill set but will also serve as a gateway to grasping the intricacies of neural networks.
Determinants of High Pay in Data Science and Programming
Since we’re on the topic of compensation, I think it’s safe to say that everyone wants to earn the highest amount possible. How do we achieve that? To gain insights of the determinants of higher compensation, we will examine the key characteristics of individuals with high yearly compensations within this survey. As our primary objective here is the yearly compensation, I refined the data first by removing "unemployed" entries and those with missing values. With just a few clicks in Graphext, I effortlessly generated clusters using various factors and compared the key differentiating characteristics among them, such as their yearly compensation amount, coding and machine learning experience, and education background.
Looking at this visual, we can see the different clusters and their sizes. I described each cluster’s characteristics - consisting of yearly compensation, experience and education - and ranked them in this table, sorted by highest compensation to lowest.
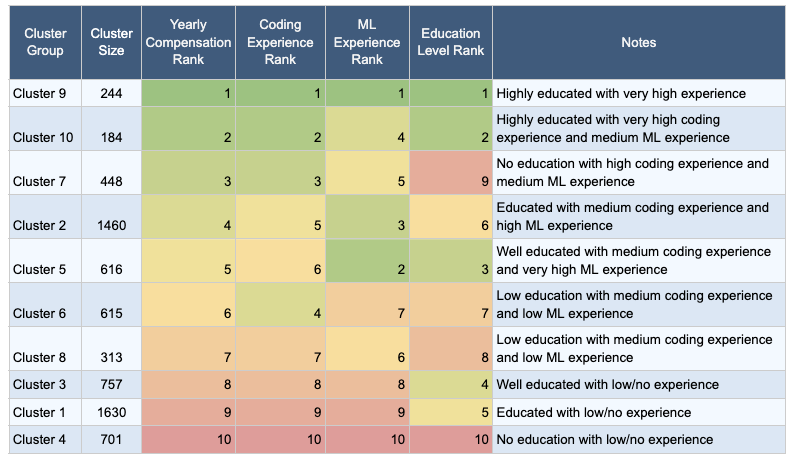
Experience Outweighs Education When it Comes to Compensation
For a clearer idea of the compensation in the cluster groups, let's look at this chart of each cluster group’s compensation distribution and compare the top 3 highest and lowest yearly compensation.
Clusters 9 and 10 have more than 50% in the $50K-200K yearly compensation group. In addition, they also have a significant number in the >$200K yearly compensation group. Specifically 23.3% in cluster 9 and 15.4% in cluster 10, both of which are notably higher than the average of 6.8%.
The 3 lowest clusters have a remarkably low average of 1.2% in the >$200K yearly compensation group and a high average of 83.6% in the $50K-200K yearly compensation group, emphasizing a higher concentration within this range.
After examining these charts, we see that experience outweighs formal education. It is an important value, with coding experience proving more valuable than ML experience. This implies that individuals without a degree can still strive for significant earnings by focusing on their skills and accumulating relevant experience and emphasizes the significance of continuous learning and hands-on expertise.
Job Responsibilities in Data Science and Programming
Are you motivated yet? Well, next you should know what kinds of responsibilities may be expected of you as part of your workload. Luckily, we have data to rely on. Here is a list of responsibilities that users in the survey had as part of their work.
A = Analyze and understand data to influence product or business decisions
B = Build and/or run the data infrastructure that my business uses for storing, analyzing, and operationalizing data
C = Build prototypes to explore applying machine learning to new areas
D = Build and/or run a machine learning service that operationally improves my product or workflows
E = Experimentation and iteration to improve existing ML models
F = Do research that advances the state of the art of machine learning
G = Others
Some of these responsibilities might be more complex than others. We will look at the number of people in charge of that workload, thus we can analyze the workforce allocation that reveals the complexity of those responsibilities. A large number assigned indicates greater complexity and a smaller number signifies simpler tasks
Responsibilities A and B mostly require fewer than 2 people whereas C,D,E, and F mostly require over 20 people suggesting their higher level of difficulty or complexity. Straightaway, these may look like a lot of responsibilities that you need to learn. But don’t worry, you don’t have to master all of them. So which ones do you need for your dream job?
Some roles like data scientists and software engineers have spread out responsibilities (A-E) which means you would need proficiency across multiple areas. Conversely, roles such as data analysts and statisticians primarily focus on a single dominant responsibility (A) therefore only needing high proficiency in that area. It is essential to identify your desired role and prioritize learning the skills you need.
Starting Your Data Science and Programming Learning Journey
Now that you are excited to begin your learning journey to get that dream job, it’s also important to identify the most effective and helpful resources by following in the footsteps of those that are already at the top. Which platforms and media sources are favored as the most helpful according to the survey?
The majority of people find online courses are the most helpful platform for learning, followed by Kaggle and video platforms.
The most favored media source that reports on data science topics is Youtube and Kaggle with only a small difference.
These insights emphasize the growing recognition of non-traditional educational sources. Community-driven platforms like these can especially help in a more personalized manner, such as receiving personal advice on online courses and having your questions answered through comments or other interactive platforms. Another instance is participating in competitions on Kaggle alongside fellow data enthusiasts to further train yourself in processing data, taking online datasets like the one we are using right now. This highlights that formal education or a university degree is not a necessity for acquiring knowledge in data science and programming.
Armed with a basic understanding of the data and programming world, you can now better plan and prepare yourself to pursue and hopefully attain your dream job!
On this page
- Understanding Job Roles and Tools in Data Science and Programming
- What are the Responsibilities and Skills for each Role?
- The Importance of Machine Learning Expertise in Data Science Careers
- How many companies already incorporate Machine Learning into their business?
- Compensation Will be Higher for ML Established Companies
- Determinants of High Pay in Data Science and Programming
- Experience Outweighs Education When it Comes to Compensation
- Job Responsibilities in Data Science and Programming
- Starting Your Data Science and Programming Learning Journey
On this page
- Understanding Job Roles and Tools in Data Science and Programming
- What are the Responsibilities and Skills for each Role?
- The Importance of Machine Learning Expertise in Data Science Careers
- How many companies already incorporate Machine Learning into their business?
- Compensation Will be Higher for ML Established Companies
- Determinants of High Pay in Data Science and Programming
- Experience Outweighs Education When it Comes to Compensation
- Job Responsibilities in Data Science and Programming
- Starting Your Data Science and Programming Learning Journey